
首页 / 新闻
华体会hth登录-CPU也能速刷AlphaFold2?英特尔:请收下这份23倍通量优化指南
Time:2024年09月30日 | Author:华体会hth登录
搅翻计算生物界的AlphaFold2一开源,各种加速方案就争相涌现。
妹想到啊,现在居然有了个CPU的推理优化版本,不用GPU,效果也出人意料的好——
端到端的通量足足提升到原来的23.11倍。
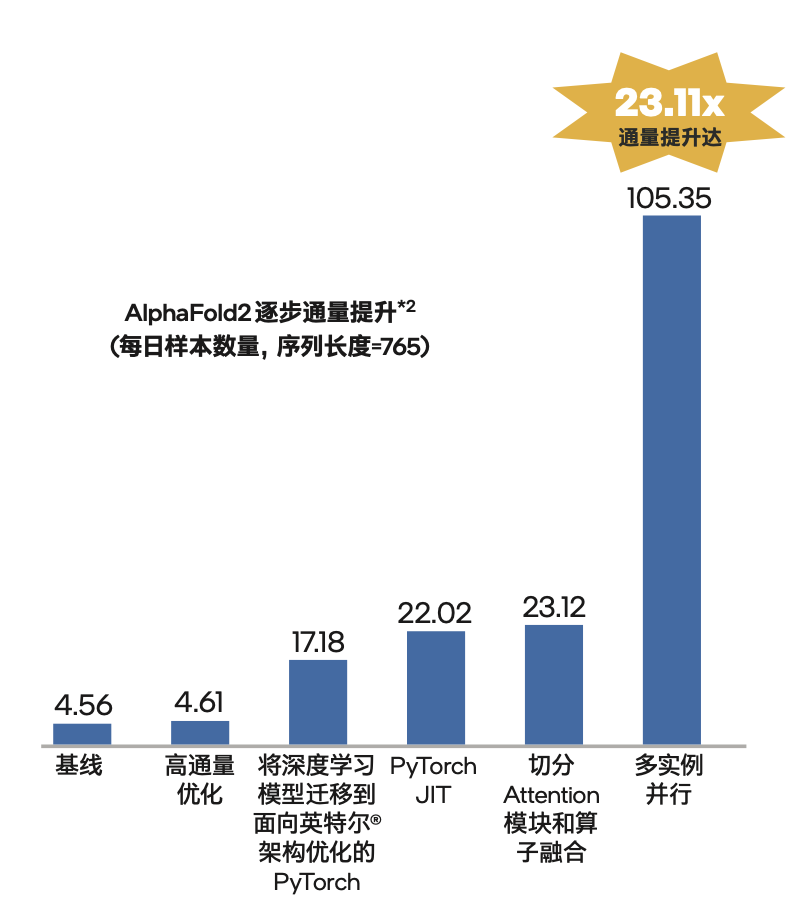
高达23.11倍的提升不是一蹴而就,但依然惊艳
换个更具体的数据,它直接让AlphaFold2的通量从每天约4.6个序列提升到了约105.4个。
要知道,由DeepMind开源的AlphaFold2,通过AI算法对蛋白质结构预测实现了接近实验精度的精准预测,可谓是公认的AI for Science标杆。
该领域也一直被认为是最吃AI专用加速芯片,如GPU红利的前沿方向。
这一最新成果的释出,就意味着CPU也能在AI for Science领域占有一席之地,并发挥巨大、而且是出乎大家意料的威力。
同样,这个成果也意味着AI for Science的入场门槛正在被拉低,对那些想从事基础科研和创新,但还没有布局异构IT基础设施,或没有大规模采用AI专用加速芯片的企业和机构而言也是个难得的福音,意味着他们依靠更常见的IT基础设施就能开展工作。
那么这个优化方案究竟是如何做到的?一起来看。
只用CPU加速AlphaFold2,优势在哪?
这在其预处理、推理、后处理三个部分都有所体现。
预处理阶段,由于输入的氨基酸序列所含信息不多,AlphaFold2一般会先利用已知信息(蛋白质序列、结构模板)来提升预测精度,以此拿到MSA表征(MSA representation)和邻接表征(pair representation)的三维张量。
这就意味着AlphaFold2属于大张量模型,在嵌入层的瓶颈不在于并行计算,而是在于内存消耗和异构数据通信。
这正是CPU所擅长的领域。
再看模型推理阶段。
该阶段通过一个由48个块(Block)组成的Evoformer网络进行表征融合。
该网络的机制是利用Self-Attention来学习蛋白质的三角几何约束信息,让两种表征信息相互影响,从而使得模型能直接推理出相应的三维结构,且要循环三次。
结构层还会基于不动点注意力机制,对三维结构的每个原子进行预测,最后合成一个高度准确的结果。
这一番动作下来,对算力是个大考验。
而且原版AlphaFold2会受到显存限制,导致能够探索的蛋白质序列长度不足1000aa。但很多蛋白质的序列长度动辄都是2k、3k。
最终在后处理阶段,将使用Amber力场分析方法对获得的三维结构参数优化,并输出最终的蛋白质三维结构。
DeepMind团队提到,他们用128块TPUv3从头训练一遍AlphaFold2,需要11天的时间。
同时,AlphaFold2代码是基于JAX的,偏向于专业从事AI科学计算的研究人员,普通开发人员部署起来也比较困难。
种种挑战之下,导致AlphaFold2自开源后,相应的加速方案也接连涌现。不过无论是训练还是推理,市面上更多见的,还是基于AI专用加速芯片,如GPU的方案。
完全基于CPU的加速方案还是头一回见,而且一上来就在性能增幅上震惊四座,推理通量可提升到优化前的23倍之多。
具体到底是怎么做的?
如何只靠CPU增效达23倍?
提到CPU,你可能已经想到方案的提出者是谁了——
没错,就是那个名字,英特尔。
他们基于目前最新的第三代至强可扩展平台,最终实现了“23.11倍”的通量优化成果(相比未优化时),其中有5.05倍是靠模型本身的优化所带来,还有4.56倍则是来自傲腾持久内存提供的TB级内存支持。

第三代英特尔®至强®可扩展处理器
其整体流程,就是先在预处理阶段对模型进行高通量优化,然后将模型迁移到PyTorch框架下,接着再在PyTorch版本上进行细节上的推理优化,最后给予TB级内存支持以解决AlphaFold2的内存瓶颈,由此达到不输专用加速芯片的效果。
更具体点,这些优化一共分为五步。
01、预处理阶段高通量优化
如前文所述,此阶段模型在进行蛋白质序列和模版搜索时需要计算平台执行大量的向量/矩阵运算——处理器能不能够火力全开就显得尤为重要。
第一步优化就在此展开,不过这步的优化非常简单,就是借助至强可扩展处理器自带的多核心、多线程和大容量高速缓存能力直接加速,提升MSA和模板搜索通量。
至强可扩展处理器内置的AVX-512指令集和支持的NUMA ( Non-Uniform Memory Access,非一致存储访问) 架构等技术,能以提供最大512位向量计算能力的显著高位宽优势,来提升计算过程中的向量化并行程度,从而进一步提升预处理阶段的整体效率。
这步优化支持所有至强可扩展系列CPU,且只需在ICC编译器中添加一句简单的配置就OK:
-O3 -no-prec-div -march=icelake-server
02、迁移到面向英特尔® 架构优化的 PyTorch
在预处理阶段的高通量优化完成后,就需要将模型迁至PyTorch了。
因为原始AlphaFold2所基于的JAX库所提供的加速能力主要针对GPU,且在英特尔®架构平台上能够发挥的功能有限。
而PyTorch拥有良好的动态图纠错方法,与haiku-API有着相似的风格(AlphaFold2一部分也基于haiku-API实现),就更别说还有英特尔®oneAPI工具套件提供的针对PyTorch的优化“利器”:Intel® Extensions for PyTorch (IPEX)。
因此,为了实现更好的优化效果,需要在这里完成 PyTorch版本的迁移。
03、PyTorch JIT
接下来,为了提高模型的推理速度,便于后续利用IPEX的算子融合等加速手段进行深入优化,英特尔又将迁移后的代码进行了一系列的API改造,在不改变网络拓扑的前提下,引入PyTorch Just-In-Time (JIT) 图编译技术,将网络最终转化为静态图。
以上都还只是“热身动作”,下面才是展现“真正的实力”的时候——
04、切分Attention+算子融合
首先,通过算法设计分析,英特尔发现,在AlphaFold2模型的嵌入层有一个叫做ExtraMsaStack的模块,其注意力模块包含了大量的偏移量计算。
这些运算需要靠张量间的矩阵运算来完成。
其过程就会伴随着张量的扩张,而张量扩张到一定规模后,就会让模型内存需求变得巨大。
比如一个“5120x1x1x64”的张量,其初始内存需求只要1.25MB,扩张过程中就可达到930MB。
这一下子爆出的内存峰值压力,会让内存资源在短时间耗尽,继而可能引发推理任务的失败。
同时别忘了,大张量运算所需的海量内存还会带来不可忽略的内存分配过程,徒增执行耗时。
那么,英特尔的第四步优化就瞄准这两个“痛点”,对注意力模块来了个“大张量切分”的优化思路,化大张量为多个小张量。
比如将上述“5120x1x1x64”的张量切分为“320x1x1x64”后,其扩张所需的内存就由930MB降至59.69MB,只占原来的6.4%左右。
没有了大内存之需,也就不需要进行内存分配了,因此,张量切分后推理速度也上来了。
比如从下图我们就可以看到,注意力模块的效率在切片前后有着非常明显的差别。

注意力模块切分前后对比
这还没完。
接着,英特尔利用PyTorch自带的Profiler对AlphaFold2的Evoformer网络进行了算子跟踪分析。
然后他们发现,有两种算子(Einsum和Add)的资源占用率很高,且总是连续同时存在。
因此,英特尔就使用IPEX工具提供的算子融合能力将它俩的计算过程进行融合,以省去中间建立临时缓存数据结构的时间,提高整体效率。
从下图我们可以看到,两算子融合后光是在单元检测中的计算效率就提升到了原来的6倍。

算子 Einsum+Add 融合效果图
至此,经过以上几个步骤的优化,AlphaFold2在CPU上的总体性能已经得到了大约5倍的提升。
还差最后一步:
05、多实例并行优化
在这一步,英特尔先利用至强可扩展平台上基于NUMA架构的核心绑定技术,让每个推理工作负载都能稳定地在同一组核心上执行,并优先访问对应的近端内存,从而提供更优、也更稳定的并行算力输出。
然后引入英特尔®MPI库帮助模型在多实例并行推理计算时实现更优的时延、带宽和可扩展性。
但这些动作还不足以破解限制AlphaFold2发挥潜能的一个重要因素:内存瓶颈。
众所周知,在面向不同蛋白质的结构测序工作中,序列长度越长,推理计算复杂度就越大。
而在我们对模型进行了并行计算能力的优化后,更多计算实例的加入还会进一步凸显这一问题。
英特尔用“星际探索”这一比喻对这种现象做了非常形象的说明。
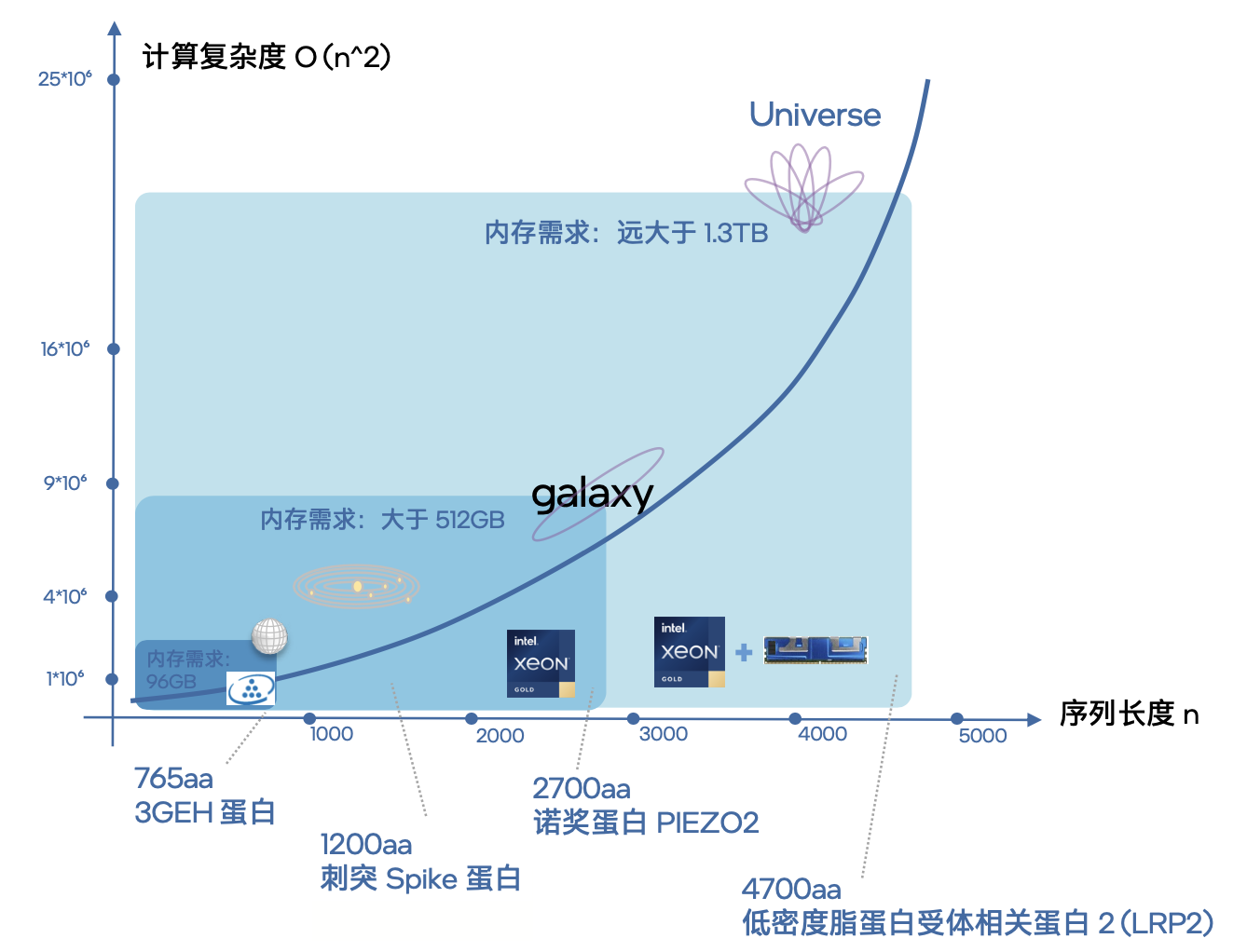
不同序列长度的蛋白质所代表的计算复杂度示意图
可以看到,当蛋白质序列长度达到4700aa时,此时内存需求就已经大于1.3TB,计算复杂度对于系统来说就相当于“探索宇宙级别”了。
如果再加上64个实例并行执行,内存容量的需求就会冲到一个令人惊叹的量级。
那么,一个具备超大容量内存支持的平台就显得尤为重要。
给至强可扩展处理器配上傲腾持久内存便可满足这一需求。

英特尔®傲腾™ 持久内存
提到傲腾持久内存,我们并不陌生。今年6月在《用CPU方案打破内存墙?学Paypal堆傲腾扩容量,漏查欺诈交易量可降至1/30》一文中已经小结了它对于AI应用的关键作用,即提供更大容量的内存子系统来满足那些内存敏感型AI应用将更多数据贴近算力的需求。
目前最新一代的傲腾持久内存200系列,可以在提供接近主流DRAM内存性能的基础上,实现每路高达4TB的容量,或者说,与DRAM内存组合时可提供每路高达6TB的内存总容量。
有了它,我们甚至能够实现10000aa序列长度的蛋白结构预测。
用了它,英特尔这个方案的优化就基本完成,模型的总体性能也可在之前优化步骤的基础上再次得到4.56倍的提升。
最后,附上一份用于这个优化方案的英特尔官方推荐配置。

AlphaFold2 高通量推理实现所需的系统——英特尔推荐配置
如果你想看更多细节中的细节,也可以访问英特尔公开分享的白皮书《通量提升达23.11倍!至强可扩展平台助力AlphaFold2端到端优化》。
或者观看英特尔联合国际学术期刊《Science》推出的“架构师成长计划”第二季第八期课程《AI驱动的生命科学创新范式之变》。
其中不但有量子位总编辑李根、晶泰科技首席研发科学家杨明俊博士和英特尔人工智能架构师杨威博士围绕这个主题的精彩讨论,还有晶泰科技在AI制药领域的领先实践分享,以及英特尔这个AlphaFold2优化方案更为细致且可视化的呈现。
经验和成果在业界已开始扩散
光说不练假把式,英特尔这个方案看起来很美,但要真正实现落地才能让人信服。
事实上,在对这个方案进行摸索和开发的过程中,英特尔与相关领域合作伙伴或用户的协作与交流就一直没停过,不但吸收了各方的经验,实现了博采众长和互相借鉴、启发。
在成型后,也第一时间广泛分享给到伙伴和用户们,让他们能够根据自身特定的环境、应用状况和需求,开展实战验证和推进更进一步的探索。
例如国内某高校就曾尝试在数百台基于至强可扩展处理器的服务器上,采用该方案提供的经验和方法来进行测试,并取得了一举两得的结果——
其顺利实践了短序列高通量的、面向蛋白质组学级别的批量化结构预测,既降低了蛋白质组的AlphaFold2预测成本,又提高了集群推理的总通量。
上文提及的国内明星AI制药公司晶泰科技,也在自身的研发中,将自主研发的AI算法与AlphaFold2结合,从而验证靶点、精确解析活性构象,为后续的药物发现打下良好基础。
通过充分利用CPU的TB级内存支持,在公有云上部署英特尔版AlphaFold2优化方案后,科学家可以实现针对短序列的单节点高通量推理优化,从而加快蛋白组学结构分析进程,并预测序列长度超过4700aa的蛋白质序列。
这不光能拓展AlphaFold2在研发中的探索范围,也能以更低的成本,让更高精度的算法工具作用于更早的研发环节,进一步加速药物发现。
蛋白质结构预测,只是AI for Science的序幕
不久前,引爆了AI for Science的AlphaFold2又公开了新进展——
它已经成功预测出包括植物、细菌、真菌在内的100万个物种的2.14亿个蛋白质结构,并将数据集对外开源。
而这些,都还只是AI for Science的序幕。
在蛋白质结构预测、生物计算、药物开发之外,AI在物理、天文、化学等领域也开始逐渐展露头角。
前沿领域,今年《Nature》上的一项“改写物理教科书”的研究,正是通过AI开展的。
欧洲核子研究组织(CERN)的科学家利用机器学习,发现了质子内部存在5个夸克的有力证据,这一成果颠覆了一直以来质子只有三个夸克的理论。
应用落地层面,前面提到的晶泰科技已经构建了一套智能计算、自动化实验、专家经验结合的三位一体的研发模式,提供一站式小分子药物发现、大分子药物发现,药物固体形态研发,以及化学合成服务。
晶泰科技目前已建成数千平的自动化实验室,与智能算法“干湿结合”,形成实验数据与算法预测间的交互闭环,保证AI算法的产业落地和交付能力。

晶泰科技
当下行业的大势所趋,就是利用AI,从生产工具、生产关系等不同维度突破科学探索瓶颈。
英特尔所提出的CPU版AlphaFold2加速方案在生命科学领域中发挥出的巨大价值就是最有力的佐证。
而这或许还只是其技术在AI for Science领域释出的一个起点。
实际上,当AI成为科学家的工具后,一种科研新范式已在应运而生。
它不同于亚里士多德时代的演绎法,不是基于经验的试错,不是将探索发现寄托在偶然的正确之上。
它也不是牛顿爱因斯坦时代的“假设再验证”,不再依赖于人类群体中极少数天才的灵光一现。
它将探索未知的基础,第一次不再纯粹基于人类群体的认知。
当海量客观存在的数据成为“初始反应物”,在以深度学习为代表的技术驱动下,科研探索的边界或许将发生前所未有的改变。
当下AlphaFold2一系列成果震惊世人,便是对此的最佳诠释。
接下来,我们可能会看到生物、医药领域之外的更多科学家,乐意将AI作为科研探索的生产力、助手,更多突破人类想象的科研成果将会涌现……
光是想想就非常期待了
Copyright © 2019 TSING MICRO.com.cn All Rights Reserved 华体会体育 版权所有 京ICP备19019133号